
Page 7 - XVI Report Health Search
P. 7
IL NETWORK
I medici e la popolazione in studio
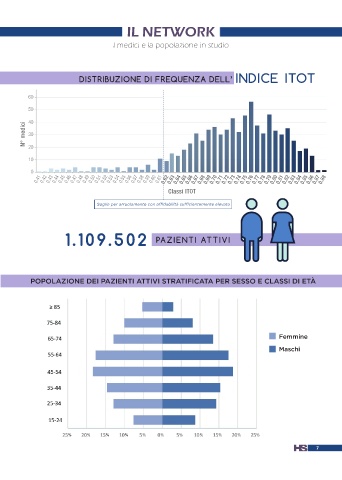
DISTRIBUZIONE DI FREQUENZA DELL’ indice itot
60
50
N° medici 40
30
20
10
0
0.41 0.42 0.43 0.44 0.45 0.46 0.47 0.48 0.49 0.50 0.51 0.52 0.53 0.54 0.55 0.56 0.57 0.58 0.59 0.60 0.61 0.62 0.63 0.64 0.65 0.66 0.67 0.68 0.69 0.70 0.71 0.72 0.73 0.74 0.75 0.76 0.77 0.78 0.79 0.80 0.81 0.82 0.83 0.84 0.85 0.86 0.87 0.88
Classi ITOT
Soglia per arruolamento con affidabilità sufficientemente elevata
1.109.502 PAZIENTI ATTIVI
POPOLAZIONE DEI PAZIENTI ATTIVI STRATIFICATA PER SESSO E CLASSI DI ETÀ
Femmine
Maschi
% % % % % % % % % % %
7